接下來的這篇文章我們要來談談 Prompt Engineering,記得這個在 2022/11 時 ChatGPT 剛出來時,這個東西很紅,走到那都在聽討論 Prompt Engineering,現在的確比較少一點,但是這個東西還是非常的重要,因為它可以幫助你省更多的錢錢和時間。
尤其是在 AI Application 成本能省則省才是好的系統
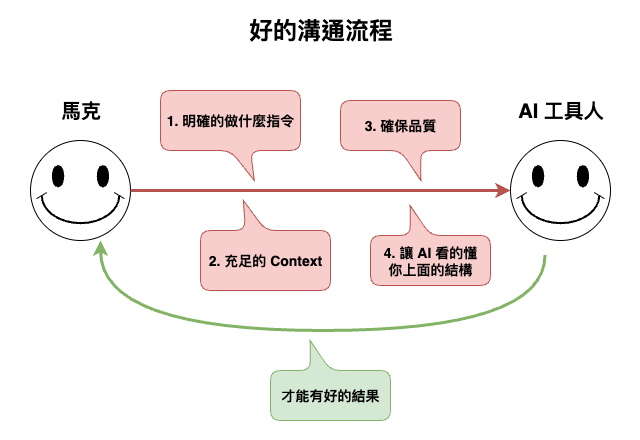
然後接下來我們講根據下圖來開始說明,要如何好好的與 AI 進行溝通 ~
定義清楚你要 LLM 做啥 ? 不要太讓它想到太多可能性。
你想想如果你說要做個聊天室,你覺得 10 個 PM 定義出來的聊天室可能會是一樣的嗎 ? 想想有在 Slack 待過的 PM 和在 Ptt 待過的 PM 定義出來的會是一樣的嗎 ?
然後以下是幾個我自已參考其它 Prompt Engineering 的文件規納出來的幾個方法。
🤔 方法 1. 明確的說出要做啥
這個我自已是覺得好像沒有一個公式,可以簡單的做出『 明確 』這個概念,然後我自已的想法就是 :
說話不要廢話,還有明確的說出要什麼,條列式我一直覺得都是明確的工具手法之一
例如下面 Google Gemini 的範例,我自已就覺得很簡單明瞭,但要我歸納明確,我好像也歸納不出啥,只能用上面的句子總結我的想法。
// Prompt ( Question )
What's a good name for a flower shop that specializes in selling bouquets of
dried flowers? Create a list of 5 options with just the names.
// Prompt ( 工作 )
Give me a simple list of just the things that I must bring on a camping trip. The list should have 5 items.
// Prompt ( 實體 )
Classify the following items as [large, small]:
Elephant
Mouse
Snail
🤔 方法 2. 給範例與輸出格式
給範例的確也是一個很好的方法,就有點像是我們在開發時,先針對 User Story 先寫測試案例,這個時後開發人員就比較不會偏離賽道想到奇怪的地方去。
這個應該在每一本溝通的書中都有提到,要讓一個人聽不聽的懂你在說什麼,有一個很重點的點在於 :
聽者理解這段對話的上下文 Context 夠不夠
例如我正在說 LangChain 相關的東西,他是如果聽的一個人是行銷人員,你覺得他會聽的懂嗎 ? 然後至於 Context 的來源有兩者 :
接下來咱們來看看有那些方法可以讓 LLM 有充足的上下文 ~
🤔 方法 1. 指定角色
指定了角色可以大大的限縮 LLM 的思考方向,不要讓他想到太多可能性,也可以先給予 LLM 有相關的上下文。
假設我們現在直接問一個 我想學習 Java 的相關知識,那接下來如果是你要回答,你會回答那一個 :
這個在我們工程師的世界,一定是直接回答 1,但問題是,如果用戶實際上是要 2 呢 ? 對吧 ? 所以實際上在說這句話時事實上沒有定義清楚範圍,所以我們應該改成如下 :
你是一個印尼專家,我想學習 Java 的相關知識
這樣 LLM 就會往印尼相關的 Java 來給你要的資訊。
🤔 方法 2. 咱們手補上下文
就是我們在 prompt 中補上上下文,這個地方水有點深,但簡單來說可以分幾個方向 :
🤔 方法 3. 選擇 LLM Model
事實上每一個 LLM 本來都會有擅長的事情,例如我們都知道寫程式碼目前應該是以 claude 相關的 LLM 最為適用,因為它大部份專門針對程式開發這塊來進行訓練的,這也代表他在程式開發的上下文充足度,應該是高於不少其它模型。
至於要去那找呢 ? 我目前大部份都是去各 AI 供應商官網看,或是在下面這個網站上看,可以參考看看。
https://artificialanalysis.ai/
🤔 方法 1. 就是和他說沒信心就說不知道
這個真希望人類也可以做到,不知道就說不知道,不要裝懂然後虎爛……
🤔 方法 2. 請他說出思考過程
如果是在比較複雜的任務情況 ( 就想成連你自已都要思考的情況 ),通常會希望他補上思考過程,這樣你可以檢查有沒有什麼問題。
🤔 方法 3. 請他說出搜尋的資料來源
怕他查的資源來源是很奇怪的網站,或是很久以前的網站。
🤔 方法 4. 列出不要他做的事情
例如我們有時後用 claude 在開發,我會補上一句,不要修改資料夾結構的情況下,來進行修改,
不然有時後沒注意到,他就直接將我們的軟體架構給搞爛了。
🤔 方法 1. 結構化 Prompt
下面這段話,仔細讀讀,應該每個人大有辦法拆分出如上述的幾個方法部份,例如要求,但就還是需要想一下對吧,我們會這樣,LLM 也會,所以為了讓他減少思考的時間就會需要 結構化 Prompt。
你是一個 AI 專家,我想要你幫我整理 LangChain 的學習知識,我現在是一個 junior enginner,所以我不太熟悉,然後請用條列式的結構給我,並且提到你查詢的來源,然後不確的就不要說。
然後接下來我們來看看結構化 Prompt 大約會長的如下,是不是一眼就可以知道整個結構,我們好理解的情況下,我自已是覺得 LLM 應該也好理解。
Context:
1. 你是一個 AI 專家。
2. 我是一個 junior engineer,不太熟悉 AI。
Instructions:
我想要你幫我整理 LangChain 的學習知識,然後請用條列式的結構給我。
Verification:
1. 請提供查詢的來源,不要是 2023 年以前的網站 ( 因為 2023 時的 LangChain 很爛… )
Additional Requirements:
1. 不確定的東西就說不知道。
🤔 方法 2. 用 Markdown 或 XML
這個地方我是看到 OpenAI 與 Claude 的文件都有提到。
使用這兩個的好處官網寫的很清楚了,我轉成中文放在這看看 :
使用 Markdown 的標題與清單有助於標示提示(prompt)中的不同區塊,並向模型傳達層級結構;在開發過程中,它們也能讓你的提示更易讀。XML 標籤可以清楚界定某段內容(例如作為參考的支援文件)的開始與結束;XML 屬性也可用來為提示中的內容定義中繼資料,供你的指令引用。
Markdown headers and lists can be helpful to mark distinct sections of a prompt, and to communicate hierarchy to the model. They can also potentially make your prompts more readable during development. XML tags can help delineate where one piece of content (like a supporting document used for reference) begins and ends. XML attributes can also be used to define metadata about content in the prompt that can be referenced by your instructions.
然後我們在一般和 ChatGPT 聊天時,可能要用這兩個會很麻煩,但是在開發 AI Application 時,我們的確可以先設計一個 Markdown Templae 然後再將用戶實際上的 Query 帶入就好。
像以下就是 OpenAI 用 Markdown 的範例
# Identity
You are coding assistant that helps enforce the use of snake case
variables in JavaScript code, and writing code that will run in
Internet Explorer version 6.
# Instructions
* When defining variables, use snake case names (e.g. my_variable)
instead of camel case names (e.g. myVariable).
* To support old browsers, declare variables using the older
"var" keyword.
* Do not give responses with Markdown formatting, just return
the code as requested.
# Examples
<user_query>
How do I declare a string variable for a first name?
</user_query>
<assistant_response>
var first_name = "Anna";
</assistant_response>
下面這個是根據上面的原則來產生出來的 Template。
# AI Prompt Template
根據以上以下的流程來回答整個問題:
1. 先從 Context 理解你的角色與相關問題的背景。
2. 在執行 Instructions 的要求,並且會參考 Example 來當你回答的參考。
3. 並且會根據 Additional Requirements 來進行修改。
4. 最後在 Verification 進行品質驗證。
## Context (上下文)
**Role:**
- [具體角色,例如:資深軟體工程師/數據分析師/產品經理]
**Background:**
- [用戶背景,例如:初級工程師/非技術人員/資深開發者]
- [描述具體情況和需求背景]
- [回答這個問題所需要的知識]
## Instructions (明確指令)
**Specific Requirements:**
1. [具體要求 1]
2. [具體要求 2]
3. [具體要求 3]
**Output Format:**
[期望的輸出格式,例如:條列式/表格/程式碼/報告]
## Example
**Input Example:**
[範例輸入]
**Expected Output:**
[期望輸出範例]
## Additional Requirements (額外要求)
- [額外的要求,例如用啥語氣之類]
## Verification (確保結果品質)
- 請提供思考過程
- 請說明資料來源
- 推理與計算類型的問題請再驗算一次。
- 如果不確定答案,請明確說「我不知道」
今天這篇文章,我們總結了幾個和 AI 有好溝通的幾個通用方法,重點事實上就是還是這張圖 :
然後下一篇文章我們將要來說說一些處理複雜任務的 Prompt 手法。


 iThome鐵人賽
iThome鐵人賽